

Nous allons voir dans cet article les commandes permettant la surveillance des composants essentiels d’un serveur tournant sous Linux. L’analyse des résultats obtenus par ces diverses commandes sera également mise en avant.
Commandes concernant le CPU
Elément essentiel de notre machine, il faut veiller à ne pas utiliser ses capacités à 100% sur une période trop longue pour éviter une surchauffe et donc de l’endommager.
Pour cela, il faut être capable de connaître les processus en cours d’utilisation. La commande top affichera l’ensemble de ces processus avec leur utilisation CPU ainsi que la durée d’utilisation depuis leur activation.
Il va être intéressant de regarder la charge système, celle-ci représente le nombre moyen de processus en cours d’utilisation ou en attente par processeur auquel est ajouté le nombre de processus bloqués.
Les commandes uptime et cat /proc/loadavg permettent d’afficher la charge système. Celle-ci est aussi indiquée dans la commande top. Une fois exécutée, la commande cat /proc/loadavg affichera 5 valeurs. Les trois premières sont une moyenne de la charge calculée sur 1, 5 et 15 minutes. La quatrième valeur représente le nombre de tâches en cours d’exécution sur le nombre de tâches lancées par le système. La dernière valeur est l’identifiant du dernier processus lancé.
Les 3 premières valeurs sont les plus intéressantes. En effet si celle-ci est inférieure à 1 alors cela signifie qu’il n’y a pas assez de processus pour occuper complètement le processeur, celui-ci exécute les instructions rapidement. Si la charge est comprise entre 1 et 2 c’est qu’il y a en moyenne un seul processus en exécution par processeur. Cependant ce processus unique pourrait être exécuté plus rapidement sur un processeur plus performant.
Pour terminer, si la charge est supérieure à 2, c’est qu’il y a des processus en attente d’entrées-sorties. Il faudra vérifier l’utilisation globale du processeur, si celui-ci n’est qu’à 10%, mais que la charge est élevée, changer pour un processeur plus performant ne résoudra pas le problème. Il faudra minimiser les E/S, analyser si la mémoire vive est suffisante. Si le processeur est à 100% avec une charge supérieure à 2, alors la faiblesse du processeur sera la cause de ce niveau élevé de la charge.
Les données importantes concernant le CPU sont situées sur les fichiers /proc/stat et /proc/loadavg.
Commandes concernant le RAM
Tout comme le processeur, la mémoire vive est un élément essentiel au fonctionnement de notre machine, en effet, elle permet de stocker les données lors de leurs traitements par le processeur.
Pour éviter une saturation de la mémoire, il faudra surveiller celle-ci grâce à deux commandes. La première qui est free n’affichera que les informations essentielles comme la mémoire totale, celle utilisée, le buffer et le cache. On pourra retrouver ces informations avec la commande top.
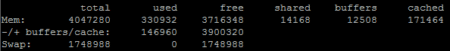
En cas de problème de mémoire, la commande cat/proc/meminfo nous fournira davantage de détails sur celle-ci. Voici un exemple de retour de cette commande :
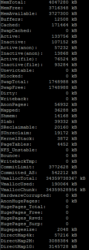
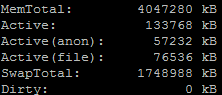
Il faudra attirer notre attention sur la ligne Active qui est la quantité de mémoire récemment utilisée, mais aussi sur le SwapFree qui représente le nombre d’octets stockés sur votre disque dur lorsque votre RAM arrive à saturation, c’est une donnée très importante. Il est possible de définir une partition d’échange sur son disque dur.Rèf : https://doc.ubuntu-fr.org/swap#definir_une_partition_comme_partition_d_echange
Aujourd’hui les serveurs possèdent bien plus de mémoire qu’il y a 10 ans. De ce fait, la valeur de SwapFree devrait être égale à celle de SwapTotal, c’est-à-dire que le Swap ne devrait pas être utilisé. Il pourra être intéressant de regarder la ligne Dirty qui représente la quantité de mémoire en attente d’être écrite sur le disque et Whriteback qui est celle en cours d’écriture sur celui-ci. Il faudra vérifier que la valeur de Dirty n’excède pas 80% de la valeur d’Active. Le calcul suivant permet de le vérifier : 100 x Dirty / Active
Etant donné le nombre de lignes que cette commande peut afficher, nous pourrons effectuer une recherche plus précise avec la commande suivante : cat /proc/meminfo | grep « nom de l’élément à afficher ». Exemple : egrep « (MemTotal|Active|SwapTotal|Dirty|whriteback) » /proc/meminfo .
Commandes concernant le Network
La commande netstat -paunt permet l’affichage des ports ouverts. Voici le détail des options :
-p : affiche le PID et son programme associé
-a : sélectionne tous les ports
-u : sélectionne tous les ports UDP
-n : affiche les IP (plutôt que résoudre les noms d’hôtes)
-t : sélectionne tous les ports TCP

Les retours de la commande sont :
Proto : le protocole utilisé. Les classiques TCP et UDP, mais également TCP6 et UDP6 pour les variantes IPV6.
Recv-Q : Le nombre de Bytes dans la file d’attente de réception. Devrait toujours être à zéro.
Send-Q : Le nombre de Bytes dans la file d’attente d’envoi. Devrait toujours être à zéro.
Adresse locale : l’adresse et le port utilisé sur la machine locale.
Adresse distante : l’adresse et le port utilisé par la machine distante.
Etat : LISTEN quand le programme écoute et attend une connexion. ESTABLISHED lorsque la connexion est établie.
PID/Program name : Le numéro de processus et le nom du programme.
Concernant le résultat de cette commande, il est important de regarder l’état de connexion des ports (ESTABLISHED lorsqu’une connexion est faite), et la quantité de données reçues et envoyées
Les données importantes concernant le réseau sont situées sur les fichiers /proc/net/dev.
Commandes concernant le Disque Dur
Afin d’analyser les entrées/sorties des disques durs, on pourra exécuter la commande iostat -dx 5 (Il faudra au préalable installer le package sysstat). Cette commande va afficher les statistiques étendues avec un rafraichissement toutes les 5 secondes.
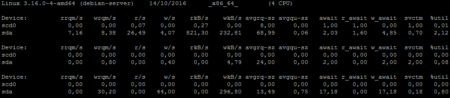
Voici les détails des éléments affichés sur lesquels il faut s’attarder :
- r/s et w/s nombre d’opérations en lecture et en écriture par seconde
- %util représente l’utilisation de la bande passante du disque, si celle-ci dépasse les 90% cela signifiera que la machine est saturée par les I/O.
Les données importantes concernant les disques sont situées sur les fichiers /proc/diskstats.
Pour aller plus loin et déceler une éventuelle future panne d’un disque dur, il est possible d’utiliser la technologie SMART qui est un protocole qui permet de suivre et contrôler l’état des disques.
Il faudra installer le package GSmartControl et exécuter la commande smartctl –smart=on –offlineauto=on –saveauto=on /dev/sdX (sdX : à remplacer par le nom du disque) qui permet d’activer SMART. La commande smartctl -H -i /dev/sdX permet d’afficher quelques informations sur le Disque choisi.
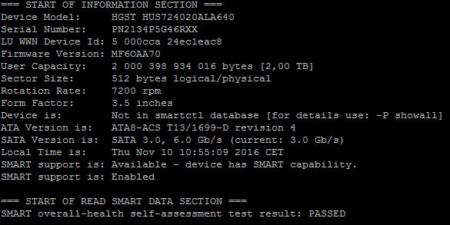
Faites la commande suivante smartctl -a /dev/sdX pour afficher toutes les informations disponibles. Voici la partie la plus intéressante dans cette commande (Disponible directement avec la commande smartctl -A /dev/sdX) :
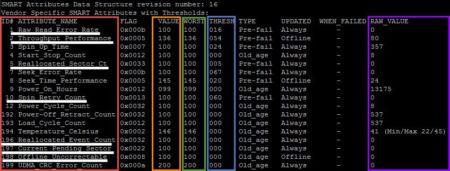
Une liste de l’ensemble des attributs ainsi que leur signification est disponible à cette adresse : http://smartlinux.sourceforge.net/smart/attributes.php. La colonne encadrée en rouge nous donne l’ID et le nom de l’attribut smart. Les valeurs des colonnes orange, verte et bleue sont des indices allant de 0 à 255. La colonne VALUE est la valeur actuelle, WORST représente la valeur minimale atteinte par VALUE. Enfin la valeur de THRESH correspond à l’indice critique, VALUE ne doit pas être égale ou inférieure à cet indice, sinon cela signifie qu’une panne ou un problème est imminent. La colonne violette représente la valeur brute de l’attribut.
Attributs importants :
- Raw_Read_Error_Rate : Indique le taux d’erreur matérielle lors de la lecture de la surface du disque. Une valeur élevée indique un problème soit avec la surface du disque, soit avec les têtes de lecture/écriture.
- Throughput_Performance : Performance générale en sortie du disque. Si la valeur de l’attribut diminue, alors la probabilité d’avoir un problème avec le disque augmente.
- Reallocated_Sector_Count : Nombre de secteurs réalloués. Quand le disque dur obtient une erreur de lecture/écriture/vérification sur un secteur, il note ce secteur comme réalloué et transfère les données vers une zone réservée spéciale (la zone de réserve). Ce processus est aussi connu sous le nom de remapping et les secteurs réalloués sont appelés remaps. C’est pourquoi, sur les disques modernes, on ne peut pas voir de « mauvais » blocs lorsqu’on teste la surface du disque (tous les mauvais secteurs sont cachés dans les secteurs réalloués). Cependant, plus il y a de secteurs réalloués, plus la vitesse d’écriture/lecture diminue.
- Spin_Retry_Count : Nombre d’essais de relancement de la rotation. Cet attribut stocke le nombre total d’essais de lancement de la rotation pour atteindre la pleine vitesse de fonctionnement (à condition que la 1ère tentative soit un échec). Une augmentation de cet attribut est signe de problèmes au niveau du sous-système mécanique du disque dur.
- Reallocated_Event_Count : Nombre d’opérations de réallocation (remap). La valeur brute de cet attribut est le nombre total de tentatives de transfert de données entre un secteur réalloué et un secteur de réserve. Les essais fructueux et les échecs sont tous comptés au même titre.
- Current_Pending_Sector_Count : Nombre de secteurs « instables » (en attente de réallocation). Quand des secteurs instables sont lus avec succès, cette valeur est diminuée. Si des erreurs se produisent à la lecture d’un secteur, le disque va tenter de récupérer les données, puis de les transférer vers la zone de réserve et va marquer le secteur comme réalloué.
- Offline_Uncorrectable_Count : Nombre total d’erreurs incorrigibles à la lecture/écriture d’un secteur. Une augmentation de cette valeur indique des défauts de la surface du disque et/ou des problèmes avec le sous-système mécanique.
La technologie SMART nous permet de faire des tests (court ou long) sur un disque et de visualiser les résultats.
Test court : smartctl -t short /dev/sdX
Test long : smartctl -t long /dev/sdX
La différence entre ces 2 tests est que la version « longue » n’a pas de restriction de temps (le court doit faire moins de 2min) et aussi que celle-ci vérifie l’ensemble du disque. Une fois la commande exécutée, il vous faut utiliser smartctl -l selftest /dev/sdX pour afficher le résultat. Attention, pour un test long les résultats seront disponibles plusieurs heures après le lancement du test. Exemple de retour pour un test court :

Explication : Depuis l’installation du paquet, 3 tests courts ont été effectués. Il n’y a pas eu d’erreurs lors de l’analyse. Afficher les résultats si un problème est détecté : smartctl -q errorsonly -H -l selftest /dev/sdX
Pour conclure cet article, on s’aperçoit qu’il existe une multitude de commandes pour monitorer l’ensemble des composants d’un serveur. Il est donc intéressant de les comprendre et de maîtriser les informations importantes qu’il en ressort. Un script reprenant ces informations peut donc être utile à réaliser.



{kind=link}