

La haute disponibilité est devenue un standard pour les entreprises, voire également un argument de vente. Vous verrez souvent marqué sur les sites de vente de service « SLA 99,99% ». SLA signifiant « Service Level Agreement », c’est l’assurance de la qualité du service fourni. Nous pourrions nous demander « Pourquoi ne pas mettre 100%, mes serveurs n’ont jamais été inaccessibles, n’ont jamais perdu la connexion au réseau ». Effectivement, dans la pratique et pour la majorité des personnes, ce taux s’approche des 100%, cependant l’informatique étant ce qu’il est, le risque zéro n’existe pas.
Des solutions sont néanmoins mises en place par les entreprises pour fournir des services hautement disponibles à leurs clients. Quelle entreprise accepterait que son site soit inaccessible pendant plusieurs minutes ?
Haute disponibilité, Hight Availability, définition
La HA se divise en plusieurs catégories, la répartition de charge, la tolérance aux pannes et la réplication des données. Des technologies existent pour mettre facilement en place une architecture hautement disponible.
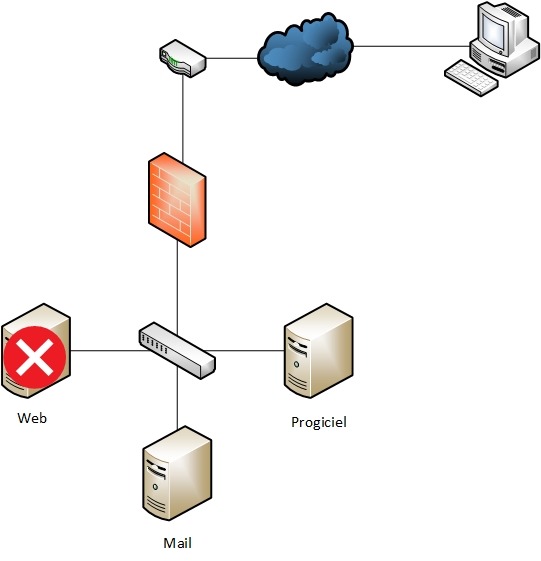
Dans un réseau d’entreprise, les services sont dans la majorité des cas répartis sur plusieurs serveurs. Dans notre exemple, l’entreprise possède trois serveurs, un serveur hébergeant son propre site web, un serveur de mail et un serveur lié à un logiciel métier. Pour accéder au site de l’entreprise, un client passe par un routeur et un pare-feu. Dans le cas où le serveur web a un dysfonctionnement, le site de l’entreprise devient inaccessible. De même, si l’entreprise subit une forte affluence, le serveur web va être surchargé et devenir inaccessible.
Répartition de la charge ou architecture en load-balancing
Toujours en partant du schéma précédent, nous allons maintenant aborder le sujet de la répartition de charge. Prenons une entreprise de vente en ligne de téléphones. Un grand constructeur fait l’annonce de son dernier smartphone et indique au public qu’il sera en prévente uniquement sur leur site internet. Suite à cette annonce, le public s’empresse d’aller précommander le fameux smartphone : en moins de dix minutes, le site de l’entreprise reçoit vingt fois le trafic qu’elle gère en temps normal, son serveur devient indisponible. Nous passerons les pertes financières et les problèmes de réputation, car le but de cet article est d’expliquer comment éviter ce problème. Une des solutions est de mettre un répartiteur de charge en tête de réseau. Il faut tout de même garder à l’esprit que si la bande passante n’est pas suffisante, le répartiteur de charge ne fera pas de miracle. Il existe des matériels qui font de la répartition de charge mais ce service peut également être installé sur un serveur ou un ordinateur. Un des répartiteurs de charge open source le plus connu est HAProxy.
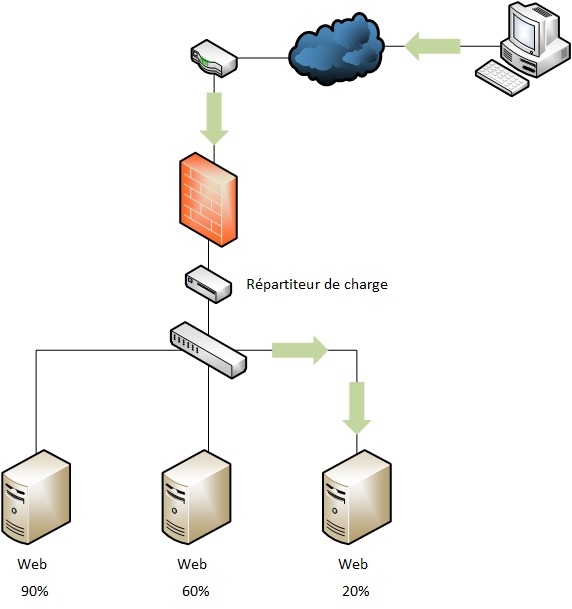
Le but d’un répartiteur de charge, comme l’indique son nom, est de répartir le flux entrant sur plusieurs serveurs. Comme montré dans le schéma, l’utilisateur va être dirigé sur le serveur le moins chargé. Le répartiteur de charge peut également gérer la perte d’un serveur. Tous les serveurs étant listés dans un fichier, si un serveur devient indisponible, le répartiteur le sortira de sa configuration pour éviter qu’un utilisateur soit dirigé dessus. Le répartiteur de charge a aussi la possibilité de générer des cookies sur le poste d’un client pour savoir sur quel serveur il a commencé sa requête et ainsi le faire continuer sur celui-ci.
La tolérance aux pannes ou architecture en failover
La tolérance aux pannes, permet de remplacer un serveur indisponible par un autre. Dans le cas étudié, le service génère une adresse ip qui redirigera les requêtes sur le serveur accessible.
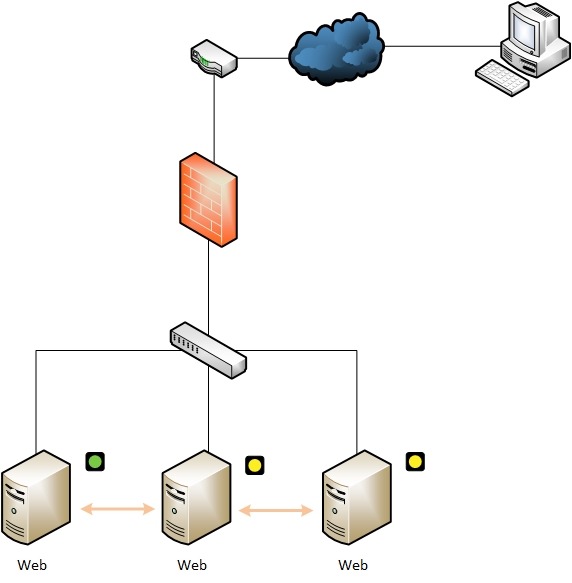
En fonctionnement normal, le client sera dirigé vers le serveur disponible. Les autres serveurs seront mis en attente. Tous les serveurs testent la présence des autres, la fréquence des tests est réglable ainsi que le temps pour considérer un serveur indisponible.
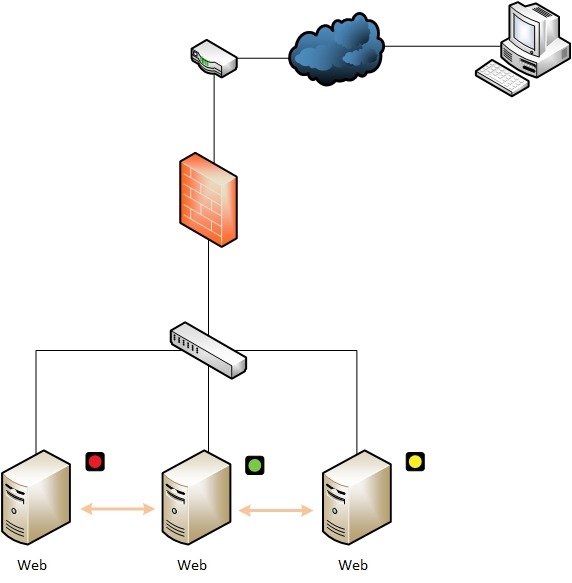
Dans le cas où le serveur principal passe indisponible, un des serveurs secondaires prend le relais. L’ordre de passage en mode actif est défini dans la configuration. Les services de type tolérance aux pannes sont à installer directement sur les serveurs. Certaines applications possèdent un service de tolérance aux pannes intégré, qui est parfois payant. Il existe aussi des solutions gratuites est open source comme Heartbeat ou Corosync.
La réplication des données dans un système à Haute disponibilité
La réplication a pour but de sécuriser la donnée en la synchronisant entre plusieurs serveurs. Cette synchronisation peut être unidirectionnelle ou incrémentale, c’est-à-dire que la donnée est écrite et accessible mais ne peut être modifiée. Souvent utilisée pour faire de la sauvegarde, cette technique permet d’avoir plusieurs versions d’un même fichier. La seconde possibilité est d’avoir une synchronisation bidirectionnelle, ce qui signifie que la donnée sera clonée entre deux ou plusieurs serveurs mais également accessible et modifiable en temps réel. Pour éviter que deux clients écrivent en même temps sur le même fichier, des systèmes de verrous et de temporisations peuvent être mise en place.
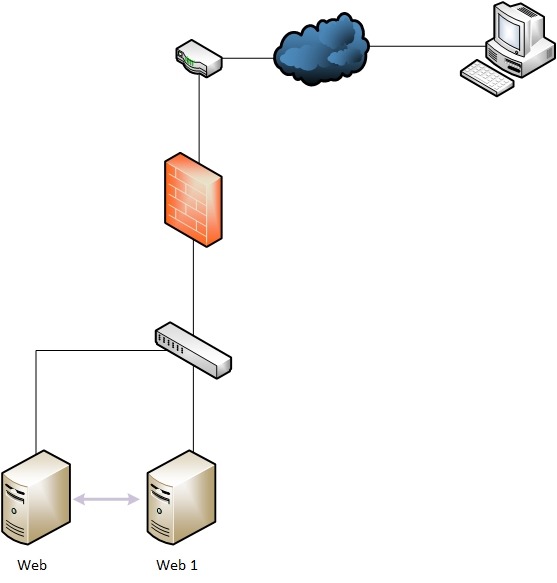
Un service est installé sur les deux serveurs et synchronise leurs données. Dans le cas de la sauvegarde, il y a un serveur primaire et un secondaire. Le client aura seulement accès au serveur primaire. Dans le cas de la réplication bidirectionnelle, le service couplé à un répartiteur de charge, permettra au client d’accéder au site internet sans se douter qu’il est sur un des deux serveurs.
Comme pour les précédents services, il existe des versions payantes mais aussi des versions open source gratuites. Pour la réplication unidirectionnelle, DRBD peut être utilisé. Pour la réplication bidirectionnelle, il existe Unison et GlusterFS.
Conclusion
Tout au long de cet article, plusieurs solutions ont été présentées pour vous permettre de comprendre la HA. Il faut cependant garder à l’esprit que la HA est un tout. Elle nécessite la combinaison de différentes technologies pour être réellement efficace. Certaines applications sont faites pour fonctionner ensemble et intègrent des plugins pour, par exemple, lancer de la récupération de données si un serveur était indisponible.
Non détaillé dans cet article, il existe également des solutions présentes directement dans les hyperviseurs de virtualisation. Ces solutions créent automatiquement des instances de services en cas de montée en charge. Ou encore, déplacer de serveur en serveur les instances si un des serveurs physiques venait à dysfonctionner.
La disponibilité à 100% n’existe pas et il ne faut pas viser les 100% car plus on va vouloir rajouter de serveurs, plus le risque va augmenter. Grâce aux communautés et entreprises, un bon nombre de solutions de HA voient le jour et il y en a pour tous les besoins.
Votre solution HA existe il vous suffit simplement de la trouver !


{kind=link}